
University of Michigan & Shanghai Jiao Tong University
I'm a senior student in the CSE Department at University of Michigan and Global College at Shanghai Jiao Tong University pursuing dual Bachelor's degrees.
I'm also doing research at Catalyst Group in Carnegie Mellon University, advised by Zhihao Jia, and SymbioticLab in University of Michigan, advised by Mosharaf Chowdhury. Previously, I was fortunate to work with Shixuan Sun at EPCC Lab in Shanghai Jiao Tong University.
My research interest lies in Machine Learning and Systems, including serving system for LLM/Robotics/Multimodality, post-training system, deep learning compiler and agentic workflow.
Education
-
 Catalyst Group, CMUVisiting Student Researcher, Megakernel Compilor and Agentic Serving SystemsApr. 2026 - present
Catalyst Group, CMUVisiting Student Researcher, Megakernel Compilor and Agentic Serving SystemsApr. 2026 - present -
 University of Michigan, Ann ArborB.S.E. in Computer ScienceAug. 2025 - present
University of Michigan, Ann ArborB.S.E. in Computer ScienceAug. 2025 - present -
 Shanghai Jiao Tong UniversityB.S. in Electrical and Computer Engineering (dual degree)Sep. 2022 - present
Shanghai Jiao Tong UniversityB.S. in Electrical and Computer Engineering (dual degree)Sep. 2022 - present
Experience
-
 MiniMaxSystem Software Intern, RL InfraDec. 2025 - Feb. 2026
MiniMaxSystem Software Intern, RL InfraDec. 2025 - Feb. 2026 -
 SymbioticLab, U-MResearch Intern, Serving Systems for Robotics/MultimodalAug. 2025 - present
SymbioticLab, U-MResearch Intern, Serving Systems for Robotics/MultimodalAug. 2025 - present -
 EPCC Lab, SJTUResearch Intern, Multi-LoRA Serving and Serverless Graph ComputingOct. 2024 - Nov. 2025
EPCC Lab, SJTUResearch Intern, Multi-LoRA Serving and Serverless Graph ComputingOct. 2024 - Nov. 2025
News
Selected Publications (view all )
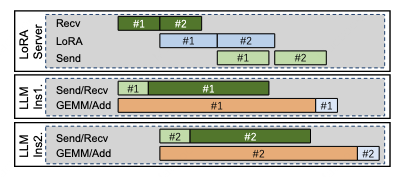
InfiniLoRA: Disaggregated Multi-LoRA Serving for Large Language Models
Hongyu Chen, Letian Ruan, Zilin Xu, Yuchen Li, Xinyu Chen, Jingwen Leng, Bingsheng He, Minyi Guo, Shixuan Sun
ArXiv Preprint
InfiniLoRA: Disaggregated Multi-LoRA Serving for Large Language Models
Hongyu Chen, Letian Ruan, Zilin Xu, Yuchen Li, Xinyu Chen, Jingwen Leng, Bingsheng He, Minyi Guo, Shixuan Sun
ArXiv Preprint
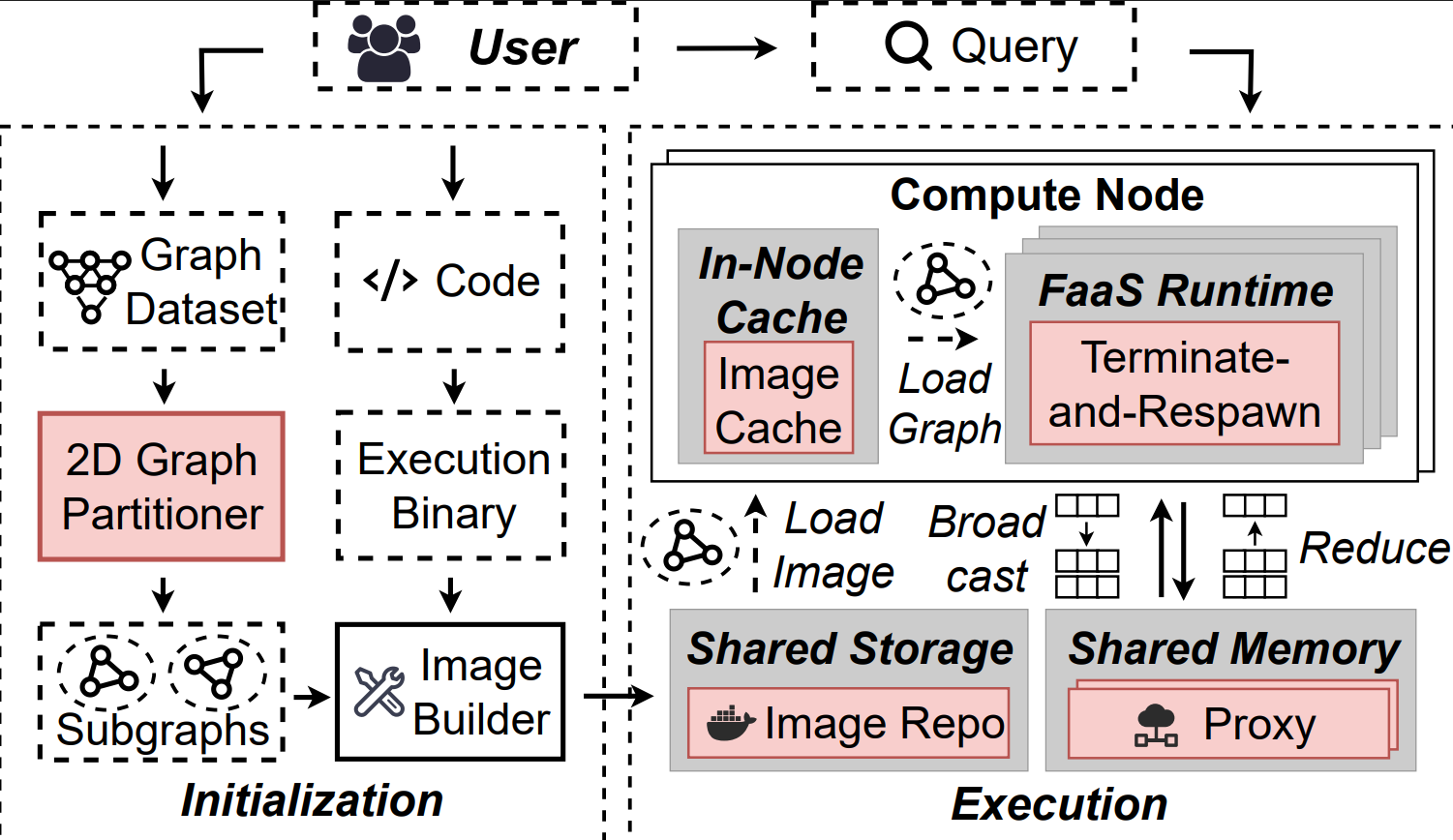
FaaSBoard: Efficient Graph Processing with a Disaggregated Architecture on Serverless Services
Yushi Liu*, Yikang Ruan*, Letian Ruan, Zijun Li, Sen Gao, Weihao Cui, Shixuan Sun, Quan Chen, Shuo Quan, Jie Wu, Bingsheng He, Minyi Guo (* equal contribution)
SIGMOD 2026
FaaSBoard: Efficient Graph Processing with a Disaggregated Architecture on Serverless Services
Yushi Liu*, Yikang Ruan*, Letian Ruan, Zijun Li, Sen Gao, Weihao Cui, Shixuan Sun, Quan Chen, Shuo Quan, Jie Wu, Bingsheng He, Minyi Guo (* equal contribution)
SIGMOD 2026
All publications
Selected Blogs
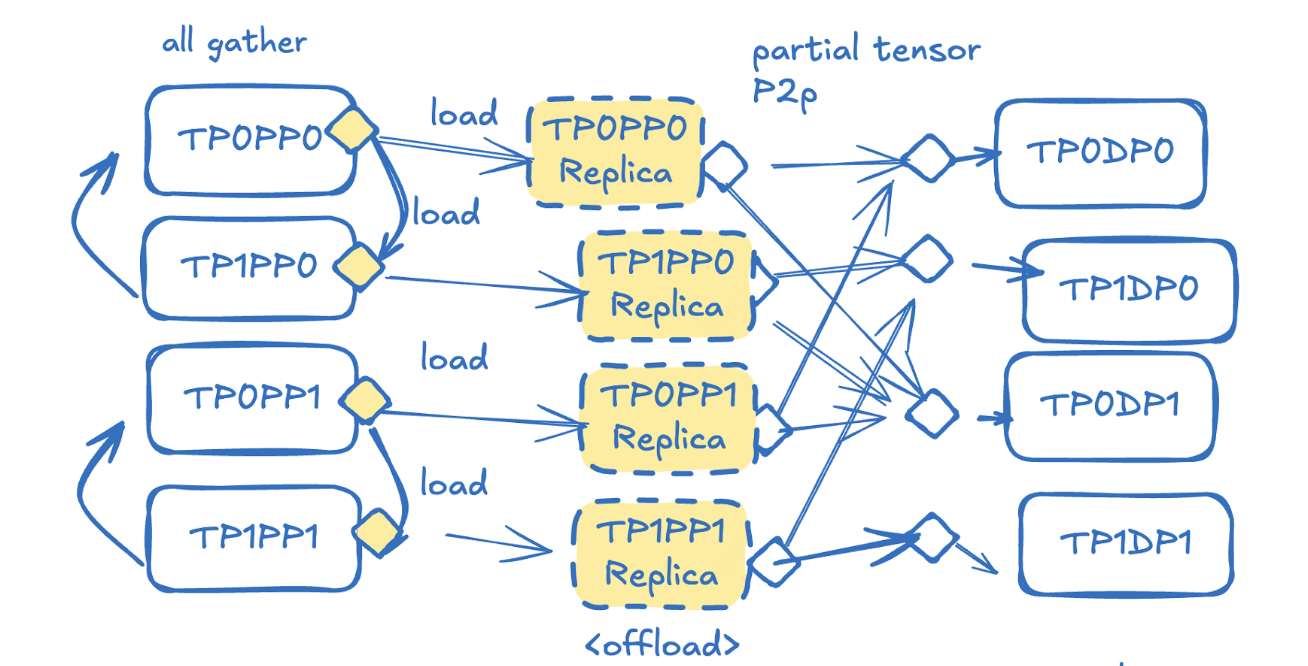
Updating 1T parameters in seconds — P2P weight transfer in Large-Scale Distributed RL
Jiadong Guo, Xin Ji, Letian Ruan, Teng Ma, Chenyang Zhao, Yueming Yuan, Zhichen Zeng
SGLang-RL Team, LMSYS.Org, April 2026
Updating 1T parameters in seconds — P2P weight transfer in Large-Scale Distributed RL
Jiadong Guo, Xin Ji, Letian Ruan, Teng Ma, Chenyang Zhao, Yueming Yuan, Zhichen Zeng
SGLang-RL Team, LMSYS.Org, April 2026
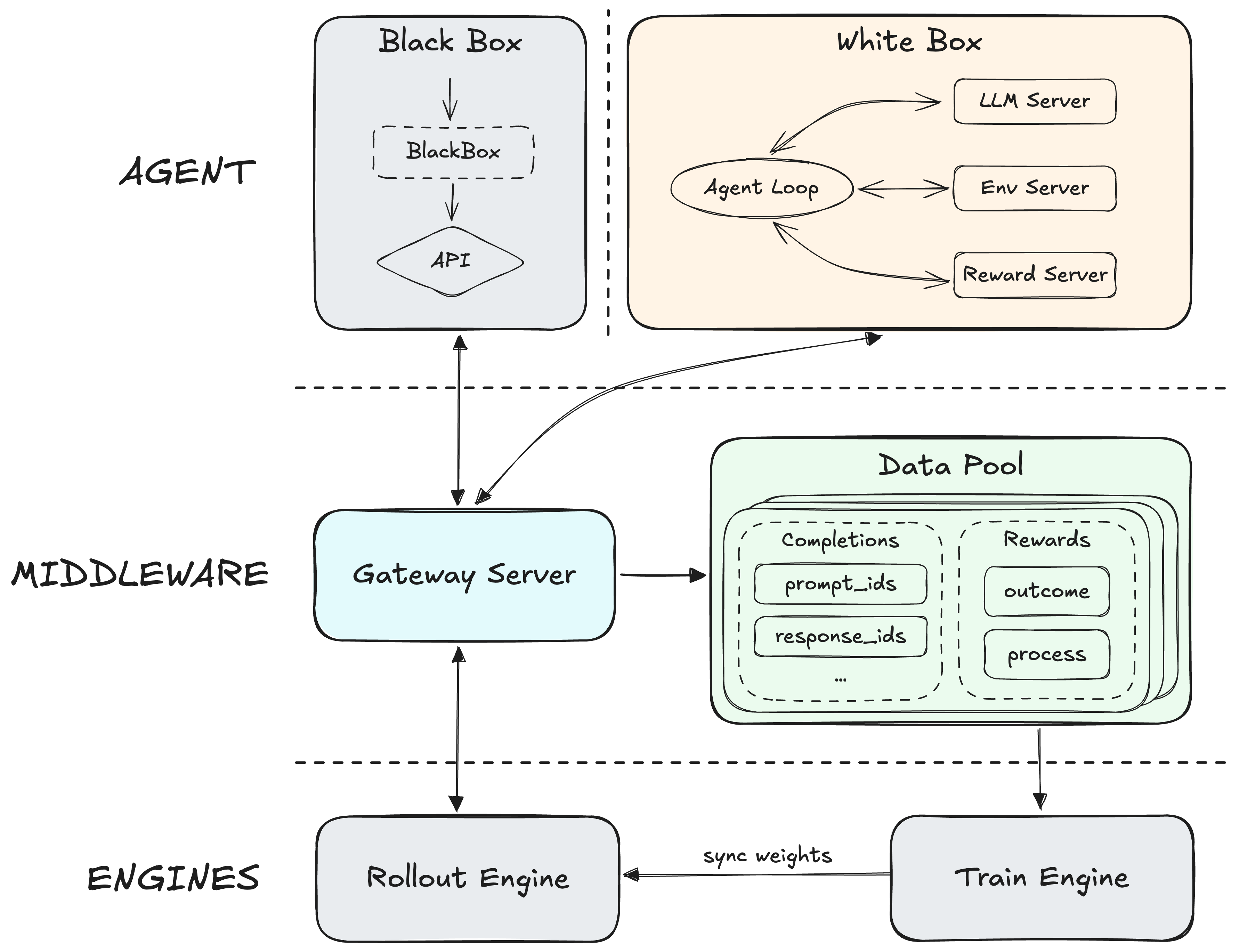
Forge: Scalable Agent RL Framework and Algorithm
MiniMax Team
MiniMax M2.5 Tech Report, Feb. 2026
Forge: Scalable Agent RL Framework and Algorithm
MiniMax Team
MiniMax M2.5 Tech Report, Feb. 2026
Open Source Projects

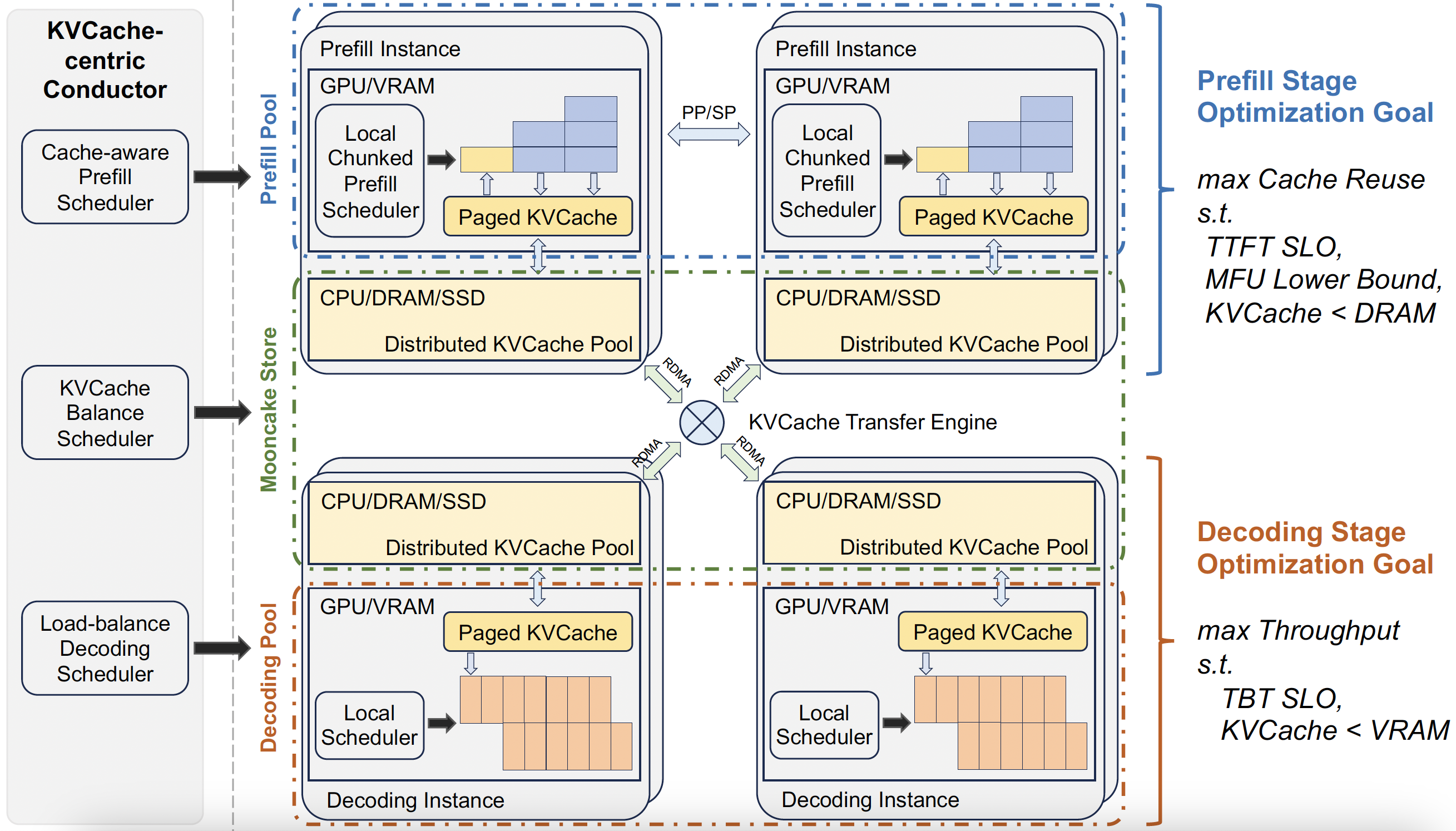
Mooncake 5.3k FAST 2025 Best Paper
Mooncake is a KVCache-centric disaggregated architecture separating the prefill and decoding clusters. It also leverages the underutilized CPU, DRAM, and SSD resources of the GPU cluster to implement a disaggregated KVCache pool.
Working on: KVCache Tranfer Pipeline.
Mooncake 5.3k FAST 2025 Best Paper
Mooncake is a KVCache-centric disaggregated architecture separating the prefill and decoding clusters. It also leverages the underutilized CPU, DRAM, and SSD resources of the GPU cluster to implement a disaggregated KVCache pool.
Working on: KVCache Tranfer Pipeline.