训推秒传万亿参数的开源实现
去年开始参与RL infra方面的工作。 当时的系统,想要更新推理测的参数需要经过硬盘 — 可想而知更新速度惨不忍睹,各个推理单元争夺硬盘带宽,直到系统的其他部分崩溃罢工。 那时候拜读了乐群的“跨机秒传RL模型参数更新的一些探索”, 惊为天人。既然自己不擅长造轮子(手搓不了新的rdma通讯库),觉得能把轮子装上,给开源社区助助力也在作出贡献。
半年之后,我们的最终成果是能在有IB的H100上把512卡,1T的Kimi fp8模型7秒传完,以及744B bf16的GLM5模型8.5秒传完,比起之前开源的解决方案快了7倍左右; 并且能够支持所有主流开源模型和两侧并行逻辑。注意这7秒包括了从推理引擎暂停(pause)到恢复(continue)的所有时间消耗,也就是整个RL训练暂停的时间。本文回溯这半年的开发历程,分享团队成员们踩过的各种坑。核心代码和使用可见Miles上的实现, SGLang的介绍,和在sglang-miles上的实现。
设计传输逻辑
乐群的系统设计是追求极致性能 — 通过实现新的底层rdma传输库,寻求权重层面上最优一对一映射来适配fsdp and 推理引擎之间的传输策略,并支持了qwen3和Kimi。 我们希望可以尽量复用现有的底层库,支持多种训练后端(megatron/fsdp),尽可能支持所有开源模型, 并行和量化设置。 为此,我们可以接受一些效率上的损失。
回到目前在 slime/miles 上的开源解决方案。 现在的UpdateWeightFromDistributed实现依赖于每个pp group的head rank和所有推理rank组建的 NCCL broadcast 原语。在源端,所有节点首先参与 TP 和 EP 维度的 all gather,在每个 PP rank 的 head rank 处生成汇总权重。这个权重会在此转换到hf格式。 随后,head rank 参与分布式更新组,通过 update_weight_from_distributed API 将完整hf权重 broadcast 到每个 engine rank,由 local rank 通过 load_weight API 加载其对应的 shard。此过程在每个 PP rank 上重复,并分桶循环运行来降低GPU内存压力。
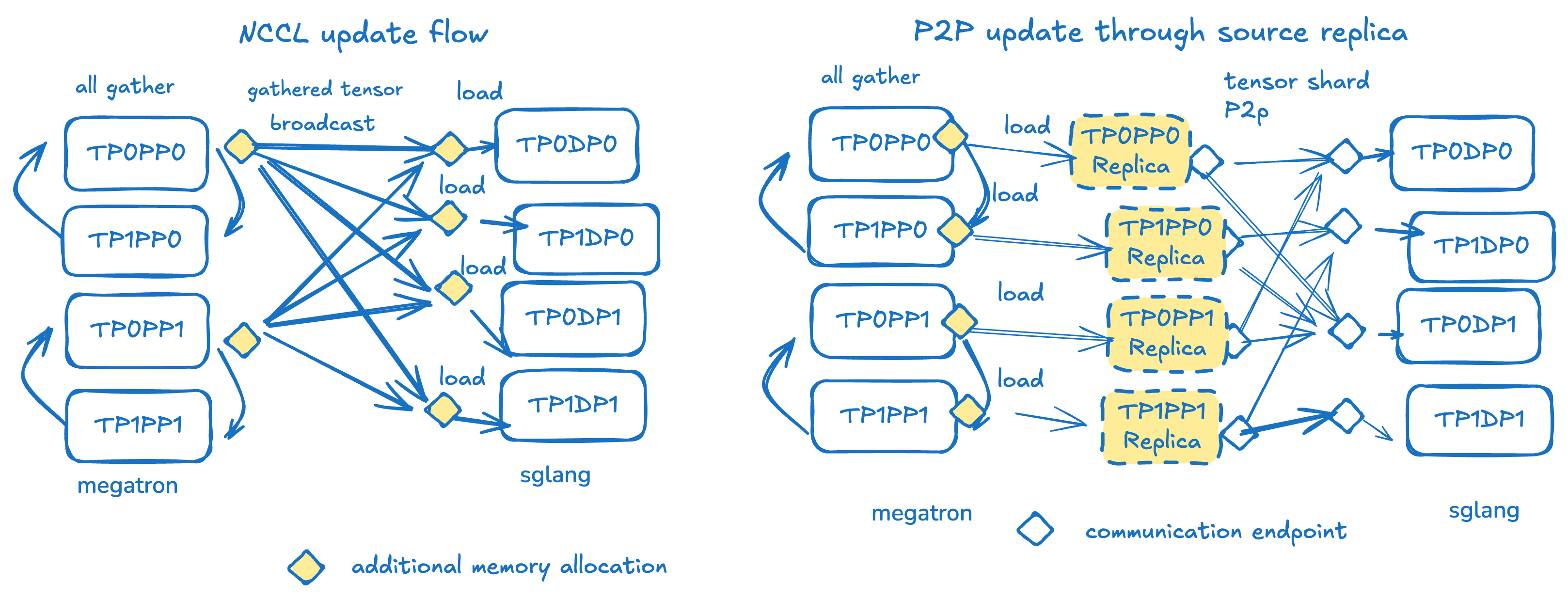
可以看到,目前开源基于NCCL broadcast的解决方案有以下问题:
- 冗余 (Redundancy): 相同的数据在网络中被多次重复发送。
- 闲置 (Inactivity): 大多数训练侧 rank 在传输期间处于空闲状态,只有少数参与 broadcast。
- 僵化(Rigidity): NCCL 通信群组在定义后无法被更新,无法支持新加入的引擎。
另一方面,这个更新范式有自己的优势: 通过hugging face full 权重作为训推交互的唯一接口,训推两侧具体的并行模式可以被完全抽象出来。 原则上它可支持任何模型,并行设计,以及量化操作。
我们这时候想到了sglang上近期支持的权重 remote fork, 一种权重远程加载的机制。 通过读取现有推理引擎的权重注册地址,新的推理引擎可以绕过硬盘读取直接快速启动。 它的传输层用了Transfer Engine来支持RDMA通信,并会自动检测网络拓扑和传输优化。 它也是目前Sglang PD分离功能的后端之一。在transfer engine 注册过的内存/显存地址可以通过RDMA协议进行网络直传,绕过kernel缓存和CPU媒介。所以轮子已经有了(RDMA 通讯库), 地址也可以通过get_remote_instance_transfer_engine_info从sglang上拿到了, 要怎么装上这个轮子呢?
设计方案1: 用rdma代替nccl
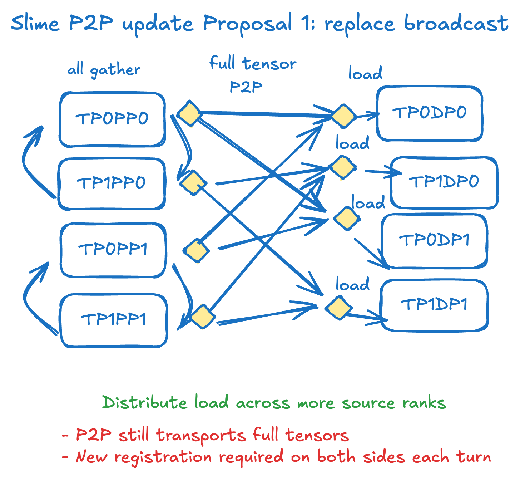
最简单的策略是替代传输策略,完全不改变任何训练和推理段的现有逻辑。在每次分桶传输时,在all gather之后,将整个hugging face 权重传输到推理端。 由于采用P2P的传输机制,这时候可以利用更多的训练侧rank来传输,看起来已经可以解决闲置(inactivity)和僵化(rigidity)的问题。
但这个设计并没能解决冗余,因为我们依旧需要传输整个模型权重到推理侧。 另外我们了解到,注册显存是个开销很大的过程,需要尽可能避免 – 但在这个方案里,针对每一个权重,在每一次传输时,我们都需要重新注册并销毁地址注册。 那有没有更优雅的解决方案呢?
设计方案2: 在训练测建一个推理引擎副本
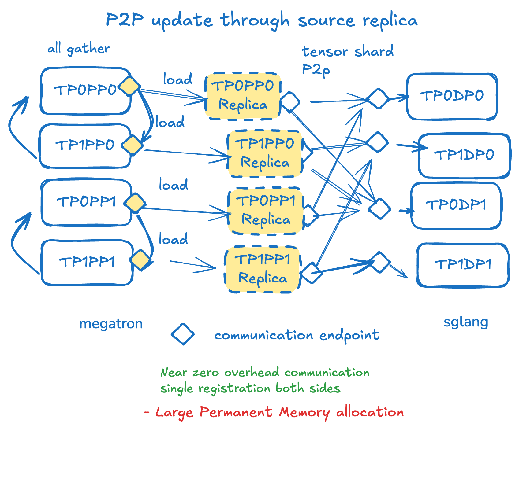
如果我们复用remote instance weight info的接口,就无需重新注册推理侧的权重。 相应的,我们可以在训练侧也预留一个推理引擎的模型副本,并进行注册。 由于这时候训练和推理侧的权重格式是完全一样的,我们只需要传输推理引擎真正需要的权重; 只需要注册一次;如果有新的引擎加入,改动也非常容易。 这看上去解决了冗余;闲置;僵化这所有三个问题!
为了实现这样一个引擎副本,我们在Sglang上添加了一个接口来导出每一个rank上的并行定义。调用的时候可以直接:
model_parallelism_info = engine.get_parallelism_config(rank)
with ParallelismContext(RankParallelismConfig.from_dict(model_parallelism_info)):
model_replica = get_model(
model_config=model_config,
load_config=load_config,
device_config=device_config,
)
训推映射关系
有了新的设计,我们只需要加上新的p2p映射关系即可。 逻辑本身比乐天当时的设计更简单— 由于我们创建了引擎副本,我们不需要考虑权重层面的传输逻辑,只需要设计训练rank和推理rank之间的映射关系即可。
已知: 每一个推理引擎必须收到所有权重。
求: 如何能在每个训练端用最少的引擎副本来满足?
答: 将每个训练 rank 映射到其目标推理侧引擎 rank。使用带负载均衡的轮询(round-robin)分配:前几个推理 rank 获得 1:1 映射,剩余目标均匀分布。
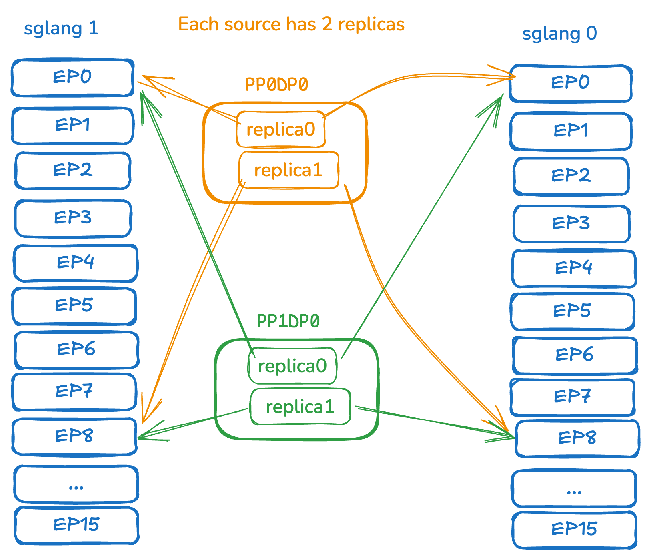
练习题: 假设训练 pp=4,有 32 个训练 rank 和 2 个 Sglang 引擎实例(每个实例 16 个 rank)。每个训练端需要几个引擎副本?
答案:在 all-gather 之后,每个 PP 组中的每个 rank 都包含了该特定 PP rank 的完整汇总权重。每个目标 rank 需要从每个 PP rank 接收权重。我们从 pp_rank=0 开始:需要将 8 个训练 rank 映射到所有 32 个目标 rank。
- 轮询映射:
src_rank 0 -> tgt_rank 0, …,src_rank 7 -> tgt_rank 7。 - 所有现有源端负载相同。进行另一轮轮询分配:
src_rank 0 -> tgt_rank 8, …,src_rank 7 -> tgt_rank 15。 - 最后,注意
tgt_rank 16与tgt_rank 0是完全等价的(属于不同实例的相同tp rank)。回顾现有分配,将相同的引擎 rank 添加到其现有源端。最终形成src_rank 0 -> [tgt_rank 0, 16]; [tgt_rank 8, 24]等。 - 以此类推到所有其他pp rank — 类似的,
src_rank 8 -> [tgt_rank 0, 16] ;[tgt_rank 8, 24]
所以每个训练端需要生成两个副本— 在训练rank0上,一个副本传到0,16, 另一个副本传到1,17.
权重映射关系和流水线更新
为了能实现分桶流水线更新,我们还需要找到hugging face权重和sglang权重之间的映射关系。 这个环节比较繁琐,本质上是剖析每个模型在sglang load_weight的过程中到底做了什么,以及什么时候一个sglang的权重彻底更新完成了。这里我们在sglang构建了一个新的类: ParameterMapper来独立解析映射关系:
sglang_name, shard_id, num_shards, expert_id, num_local_experts = parameter_mapper.map(hf_tensor)
只有当所有 num_shards 以及所有的 num_local_experts 都更新完毕后,我们才能用transfer engine发送该 Sglang 权重。
每当一个副本里的权重更新完成,我们把任务递交到一个Threadpool里,由transfer engine解除GIL并负责传输。因此在主线程上,只需要做all gather and load weight:
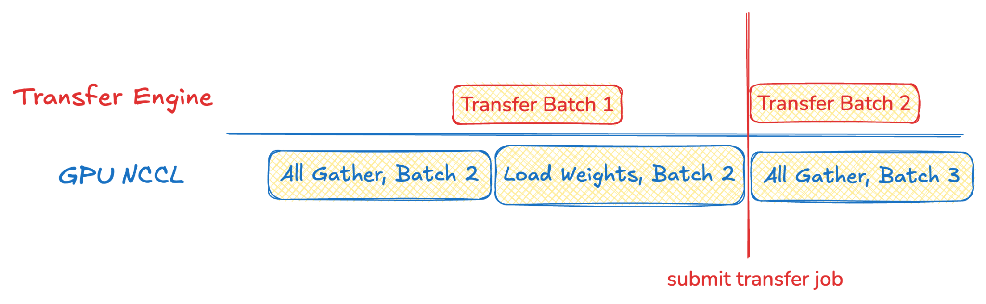
写成伪代码:
for hf_tensors in all_gather(self.bucketed_update()):
ready_tensors = []
for hf_tensor in hf_tensors:
sglang_name, shard_id, num_shards, expert_id, num_local_experts = parameter_mapper.map(hf_tensor)
ready_tensor.append(self.is_tensor_ready(sglang_name, shard_id, experd_id))
for engine in local_engine_replicas:
engine.load_weight(hf_tensors)
for target_rank in self.get_target_ranks(engine):
submit_transfer(ready_tensor, target_rank, self.thread_pool)
我们用slime/miles自带的check weight equal flag来验证传输得到的权重和预先准备的硬盘上的权重能做到一一对应,以证明正确性。
这里有一个有趣的插曲:最初我们考虑到大规模 EP/TP 场景下 P2P 连接数可能较多,专门为每个传输线程分配了独立的 transfer engine 实例,以 engine pool 的形式来分散高负载下的并发压力。然而后续实验表明,transfer engine 内部已经具备了相当成熟的高并发调度与连接复用机制,多个传输线程完全可以共享同一个 transfer engine 完成传输。收敛到单一实例后,不仅减少了 NIC 等硬件资源的重复初始化开销,还规避了多个 transfer engine 各自注册的 memory region 无法跨实例共享的问题。
初战告捷 235B
在Qwen3-4B上跑通之后,我们马上在Qwen235B上也成功跑通了bf16的64卡传64卡, 3.5秒左右, 对比原先的nccl快了三倍多。 但和miles的maintainer聊过之后,我们意识到这个方案有致命缺陷: 额外占用的显存会极大得影响训练效率 — 无论是迫使batch size变小,开启cpu offload或者checkpointing, 都会大幅降低训练速度。我们必须想办法在训练期间想办法释放这部分显存。
我们于是开始尝试在训练期间把引擎副本放上CPU,等到更新完成需要传输之前再挪回GPU。
显存优化尝试1, torch memory saver
第一个优化思路,是尝试用torch memory saver确保虚拟显存地址(virutal address)不变,以此来允许同样的地址注册被复用。 Sglang用torch memory saver实现了offload功能, 允许编译好的CUDA graph复用同样的虚拟地址,不同的物理地址。
可惜的是,我们尝试之后才发现transfer engine 目前并不能直接支持虚拟地址。 RDMA传输的本质是绕开OS kernel管理,由显卡驱动(Driver)直接通过linux 内核(kernel) peermem在NIC网卡上注册静态映射表(Memory Trasnlation Table)。 目前peermem的注册并不支持新的CUDA 内存管理接口(VMM API)。要改动网卡上的静态注册(MTT),需要繁琐的硬件锁和动态地址追踪才能保证正确性,因此目前没有广泛支持。这也是为什么miles里只能有限支持VMM API,在权重传输和DeepEP的场景之下必须换回cudaMalloc来分配显存。
显存优化尝试2, 流水线优化
另一个思路是,通过流水线优化尽可能把注册和注销显存的操作藏在ep,tp allgather之外。 在多次torch profiler之后我们发现,235B模型的显存注册事件本事就能达到6秒左右,远远超过了传输本身 — 这意味着这个方案也是不可行的。
显存优化尝试3, 不用显存
忽然我们意识到,为什么要用显存做传输发起方?Transfer Engine同时支持内存和显存 — 我们完全不需要把它重新onload到GPU上。 测试后我们发现,传输效率本身并没有受到影响!唯一的性能影响是all gather聚合后的权重需要先d2h传到CPU上。 并且,由于注册发生在内存而不是缓存上不需要通过CUDA, 注册时间也更快了。
未来显存优化尝试,Huge Page
从马腾老师这里我们了解到GPU注册时间长的本质原因是OS的默认页尺寸(page size)太小(4kb),造成注册一个常见的模型需要大量的页,造成页表项(Page Table Entries)数量过载。虽然 GPU 数据流不经过 OS,但 RDMA 注册(控制流) 必须经过内核驱动。若以默认 4KB 粒度注册 80GB 显存,会产生约 2000 万个页表项,内核在锁定物理地址并同步到网卡 MTT 表时,巨大的 CPU 循环导致了秒级延迟。 如果自己建一个可以支持Huge Page的MemPool给pytorch调用,完全是可以将注册时间控制到一个合理范围之内的。马腾老师的实验里,用32MB的页尺寸注册时间可以压缩到2秒之内。 这也是将来一个可以考虑的优化方向。
内存OOM!
在接下来的实验里,我们开始攻克GLM4.5 (335B (32B active)), 可是却在64 → 64卡的实验里遇到了内存OOM。 在训练端,我们有TP=8, EP=8, PP=8, CP=2, ETP=1, 8 节点, 推理端TP=32, EP=32, DP_ATTN=4, 8 节点,两侧都是bf16,我们现在的设计占据了多少内存?
答:训练端8个节点,并且pp=8,意味着每个节点(0-8 rank)需要传权重给所有的推理侧rank,也就是每个节点必须存有一整个推理模型的权重! 实际情况是,由于开启了dp attention,非专家部分的权重存储存储4倍,也就是(340B + 15B*4) * (2 bit/tensor) → 每个节点上需要占据整整800G的内存, 难怪它立刻就OOM了。 每个rank需要4个推理副本,总共32个副本,都存在这个节点的内存里。 常见的H100节点内存一般在1-4T区间,这个消耗无法接受了。
共享副本和流水线更新
这时候我们注意到,sglang引擎里的每个rank,本质上模型结构是完全同质的(除了最新的EPD)。 也就是说,每个rank的每个tensor,本质上是同样的尺寸和格式,只是数值有区别。 因此,我们可以让每个rank上所有的引擎副本,都共享同一个物理内存(shared replica)。
在具体实现上,我们维护每一个副本的weight loader(他们会自动抽选自己需要的shard),但是让物理内存被分享。在每个rank上,我们只需要维护一份权重,和一个ParameterMapper。
with ParallelismContext(parallelism_config):
model = get_model(
model_config=ModelConfig(model_path),
load_config=load_config,
device_config=DeviceConfig(device="cpu"),
)
if first_engine_rank:
for param in model.parameters():
param.data = param.data.pin_memory()
self._shared_params_dict = dict(model.named_parameters())
self._shared_param_mapper = ParameterMapper.from_model(model)
else:
for name, param in model.named_parameters():
param.data = self._shared_params_dict[name]
这时候我们需要注意传输的正确性。 同样的引擎副本会被传输到不同的目标引擎上,必须保证旧的传输完成之后才能载入新的权重。我们依然复用之前的Threadpool,但发送任务前要确认是否需要等待任务完成才能继续下一步的all gather and load_weight操作。 还是以之前的传输为例子,训练侧的rank 0 要用两个副本传给4个目标rank:

传输加速 1T fp8 模型, 7 秒
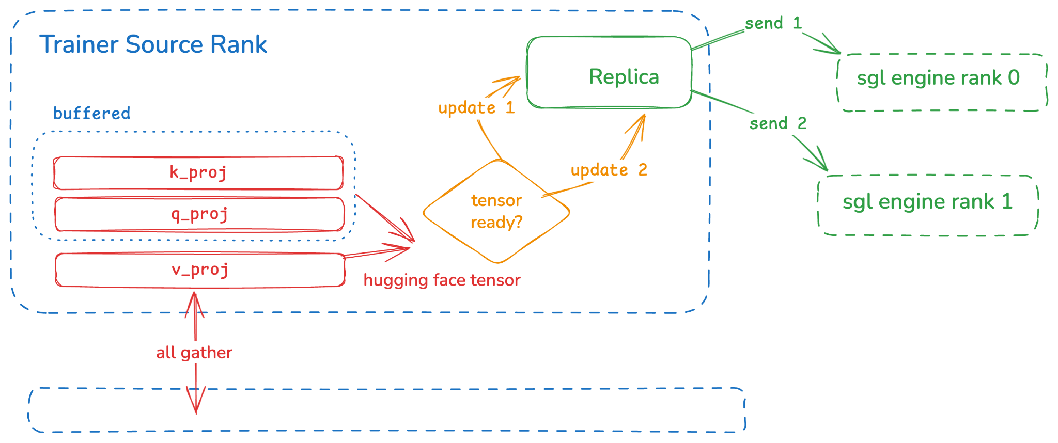
在这一系列优化之后,我们最终在512卡H100, 1T 参数的Kimi模型上跑到了7秒的传输时间。 相比起Miles原生的NCCL解决方案快了整整7倍!
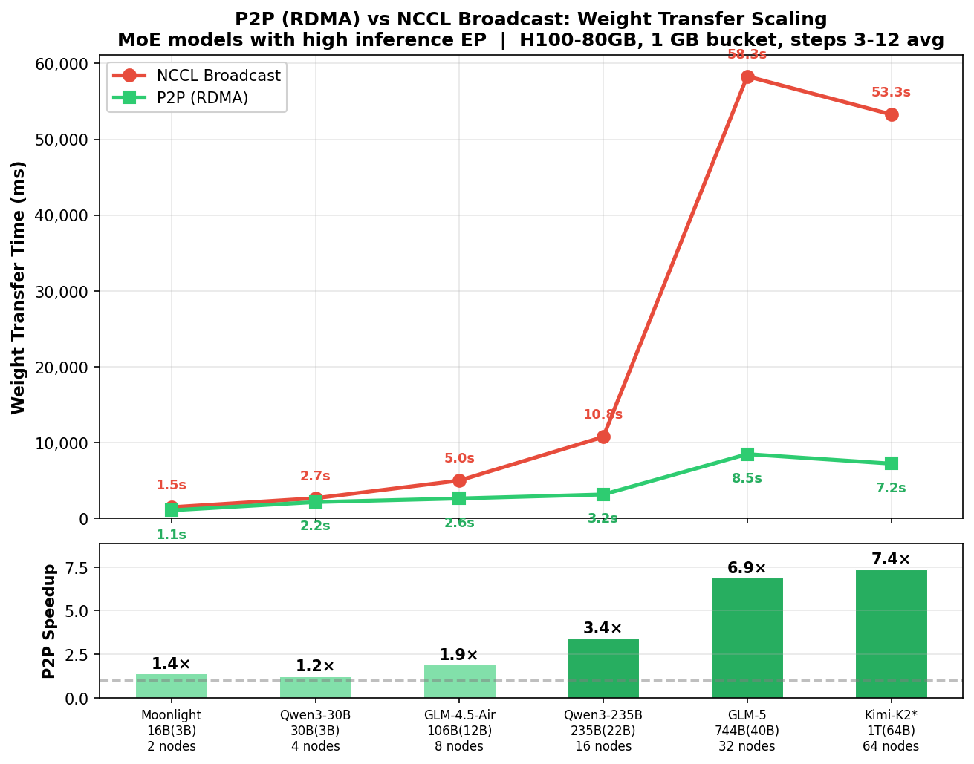
成果配图。有意思的是GLM5 32节点的速度甚至比Kimi更慢 — 应该是因为Kimi用了fp8,所以总数据量反而更多。 从这个表看来我们的 解决方案应该是可以继续scale下去的,而且是越稀疏,效果越好。 也欢迎大家分享各自的痛点和使用体验,在不久后也会加入B卡的支持。